Fedora is the underlying repository
Digirati offers a hosted Digital Preservation solution that integrates with IIIF Cloud Services but is completely independent of it. It uses Fedora 6 as the underlying repository, storing content in Amazon S3 with replication to multiple regions, other cloud providers and also your on site storage.
It is designed for simplicity of integration and long term sustainability of preserved content. Your own workflows and custom integrations do not use the Fedora API directly. Everything goes via two simplified APIs that sit in front of Fedora.
All data is mediated via two simplified APIs
The Storage API
This low level API is used to get content in and out of Fedora. It is based on only a few underlying storage concepts in Fedora - Containers (folders), Binaries (files), and Archival Groups (logical versioned preserved objects, that comprise multiple containers and binaries).
The Storage API could be said to face Fedora, abstracting away the complexities of its REST API into a few simple operations involving JSON payloads over HTTP. The Storage API uses two additional concepts - import jobs and export jobs. Both of these are JSON objects sent to the API to either ingest some files and folders from a given location to create a new Archival Group (or new version of an Archival Group), or to export the contents of an Archival Group to a specified location.
The Preservation API
If the Storage API faces Fedora, the Preservation API faces your systems and workflows. Its operations are based on preservation practices rather than simply storage. It introduces an additional concept not present in the Storage API - a Deposit. This is a workspace in which you evaluate and assemble content, and optionally run analysis tools on the files.
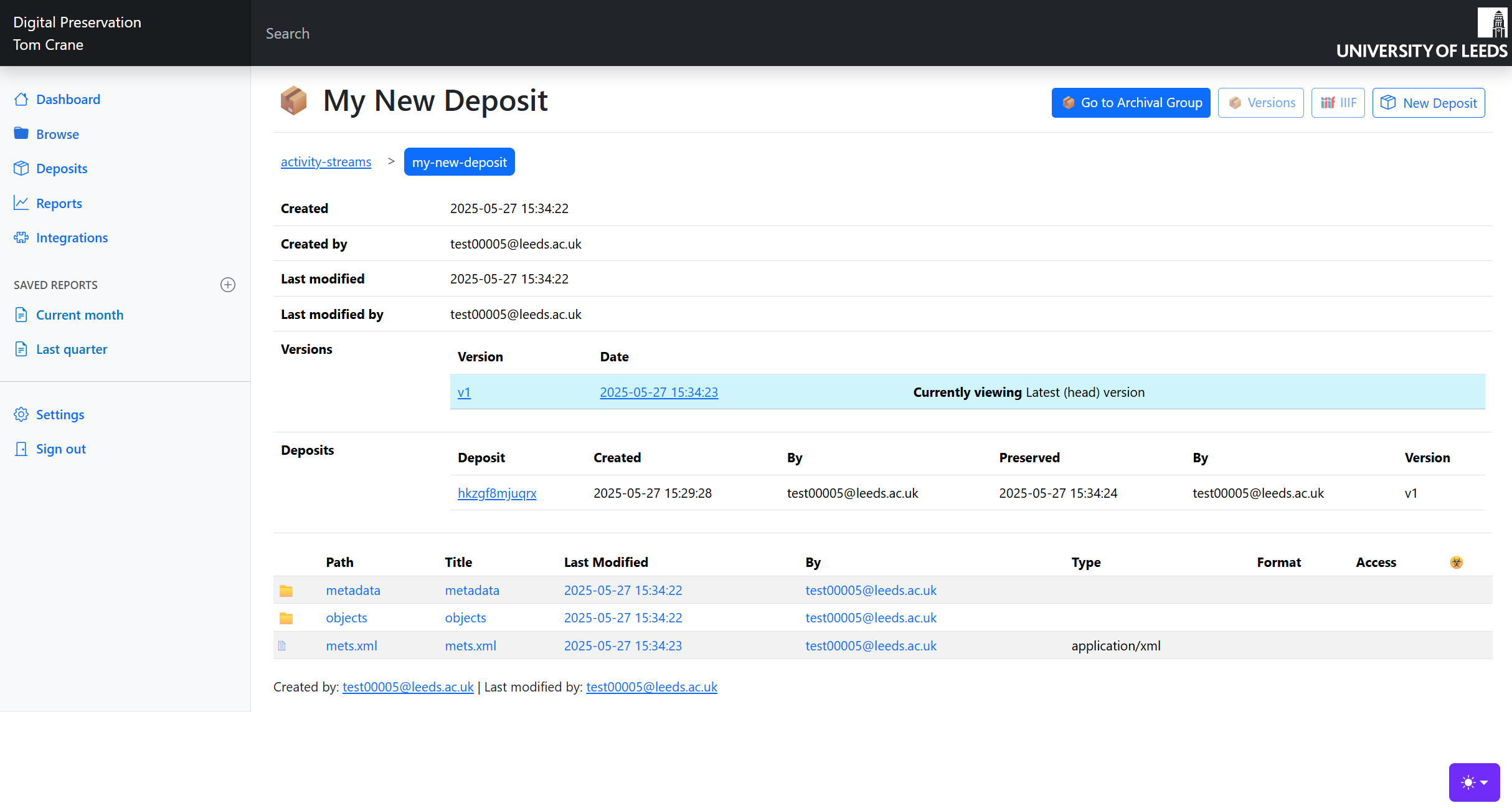
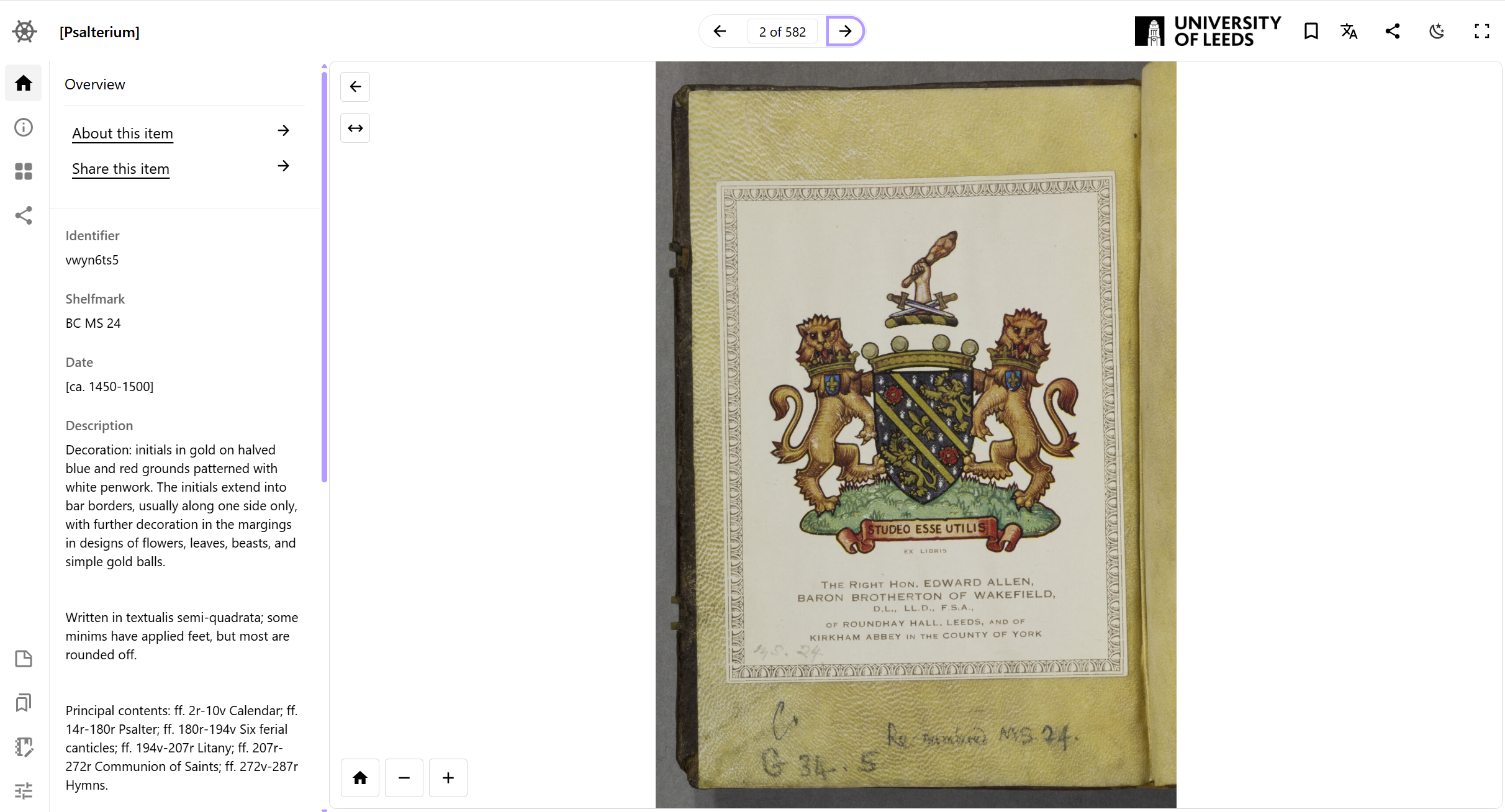
The Preservation API also understands what a METS file is, and can read METS files you might bring in with content from other systems, and create new METS files for preserved objects you create via the API and tools. In addition, a Preservation web application provides a collaborative user interface environment to create deposits and browse the repository.
A typical systems integration involving preservation workflows would only use the Preservation API; the only consumer of the Storage API is the Preservation API.
Additional considerations for the design
The Oxford Common File Layout
The choice of Fedora 6 as the underlying repository is not only down to its long-established community of users and developers, but the fact that in version 6 it now stores the preserved content in compliance with the Oxford Common File Layout (OCFL). This means that not only can the contents of the repository be reconstructed from the file system alone (no database backups or other more fragile artefacts are needed), but that it doesn’t necessarily even depend on Fedora to make sense of the preserved objects; the OCFL specification gives meaning to the arrangement of files on disk (or cloud storage) including the version history of digital objects.
We don’t reinvent the wheel
The Preservation API encourages the use of established tools and processes (for example, forensic tool use in BitCurator) rather than imposing a new set of tools or workflows on users. It reads and processes tool outputs as you work on material in a Deposit.
It is not a workflow management system; you might already have one of those, or use ad-hoc processes that the Preservation API and UI can fit into.
Bring your own modelling
Any structural meaning to the arrangement of binaries and containers in an Archival Group is unknown to the Preservation API. The answer to the question “how would I model a book” is that it’s up to you. You might choose to model in METS, or any other format that gets stored in the digital object; the METS file is just one of the stored binaries.
Integration with IIIF Cloud Services
The diagram below shows how Preservation sits with other systems at Leeds University Libraries:
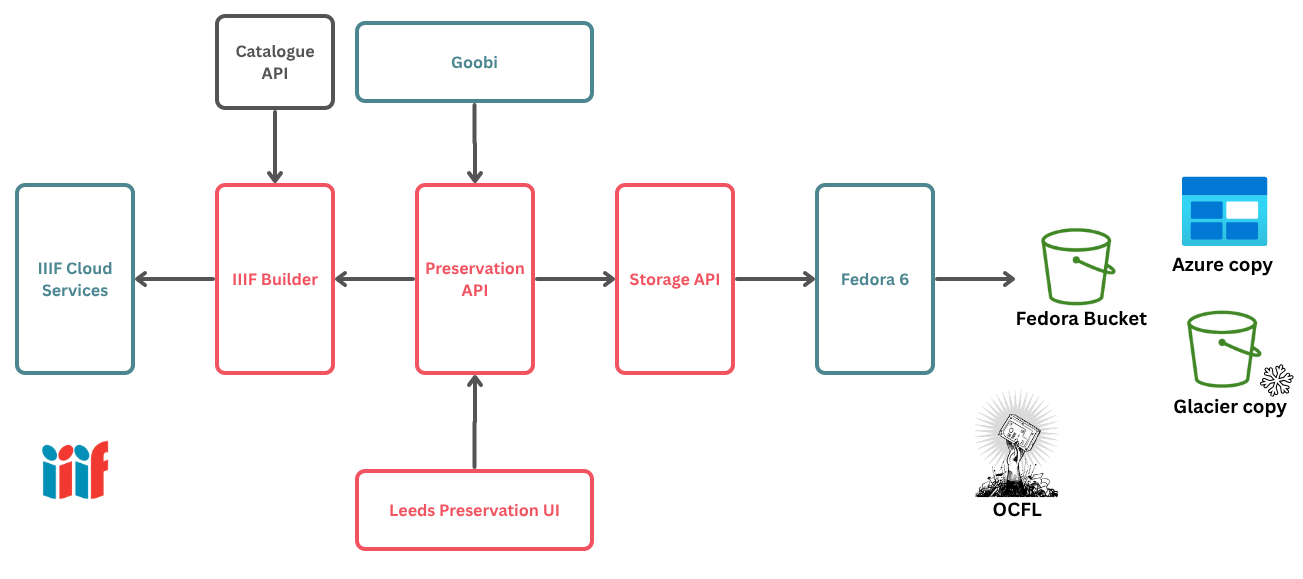
In this example a customised bridge links the objects in digital preservation to IIIF Cloud services: the IIIF Builder process. At its very simplest this process uses a IIIF Manifest template and echoes the sequence of content resources in a METS file into that IIIF Manifest, providing IIIF Image API endpoints, transcoded AV and file access as appropriate.
In most scenarios, IIIF Builder is customised to add specific descriptive metadata and other information to the Manifests. It can also be customised to translate access control information from a METS file into the IIIF Authorization Flow API in IIIF Cloud Services by integrating with your identity provider.